LoHoRavens Benchmark Examples
Baselines
Imitation Learning based model (IL)
We use the same architecture and training recipe as CLIPort for the imitation learning baseline. Using multi-task training, the CLIPort model is trained with the train sets of all 20 seen tasks along with the three pick-and-place primitives for 100K steps. Because the vanilla CLIPort does not know when to stop execution, following Inner Monologue and CaP, we use an oracle termination variant that uses the oracle information from the simulator to detect the success rate and stop the execution process.
Planner-Actor-Reporter based model (PAR)
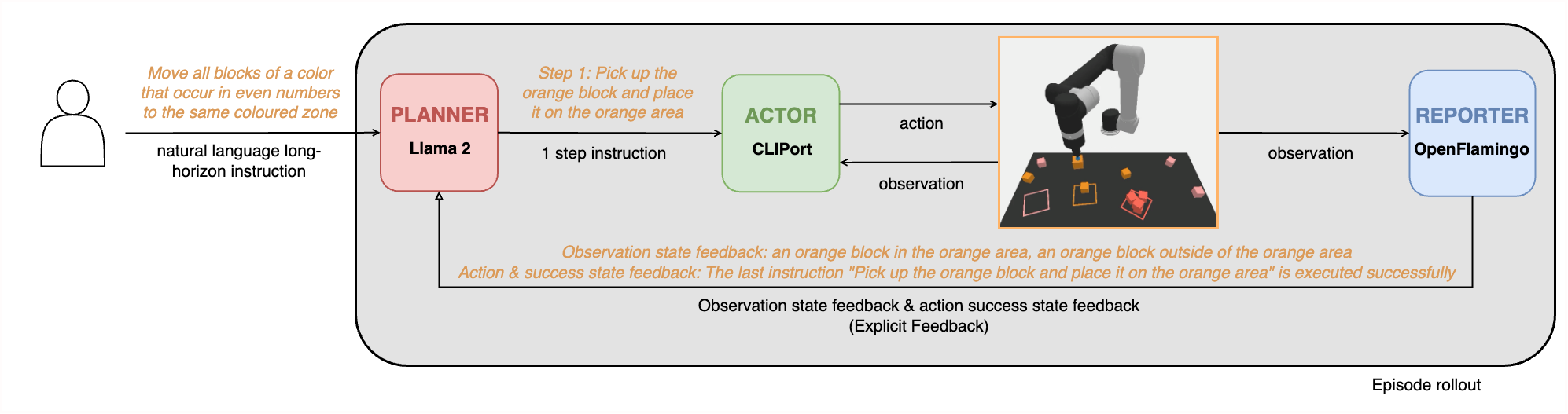
The Planner-Actor-Reporter paradigm is frequently used in robotics. Usually, LLMs serve as the Planner due to their impressive planning and reasoning capabilities, and humans or VLMs play the role of Reporter to provide necessary language feedback for the Planner's planning. The Actor is the agent that interacts with the environment.
As shown in the above figure, we use Llama 3 8B and the trained pick-and-place CLIPort primitive as the Planner and Actor, respectively. For the Reporter, we use the VLM CogVLM2. Theoretically, any type of feedback from the environment and the robot can be considered to inform the LLM planner as long as it can be stated verbally. However, considering the LoHoRavens simulated environment and the VLMs we use, we just prompt the VLMs to generate the following types of feedback:
- Observation state feedback: Besides the human instruction at the beginning, the Planner needs to have the information about the objects on the table for the planning. Furthermore, if the states of the objects change, the VLM Reporter should describe the changes to the LLM Planner.
- Action success state feedback: The robot Actor may fail to complete the instruction given by the LLM Planner. This kind of success state information (or rather failure information) should be conveyed to the Planner. The VLM Reporter will indicate in its description whether the last instruction is executed successfully or not.
More baselines are being added ...
Results
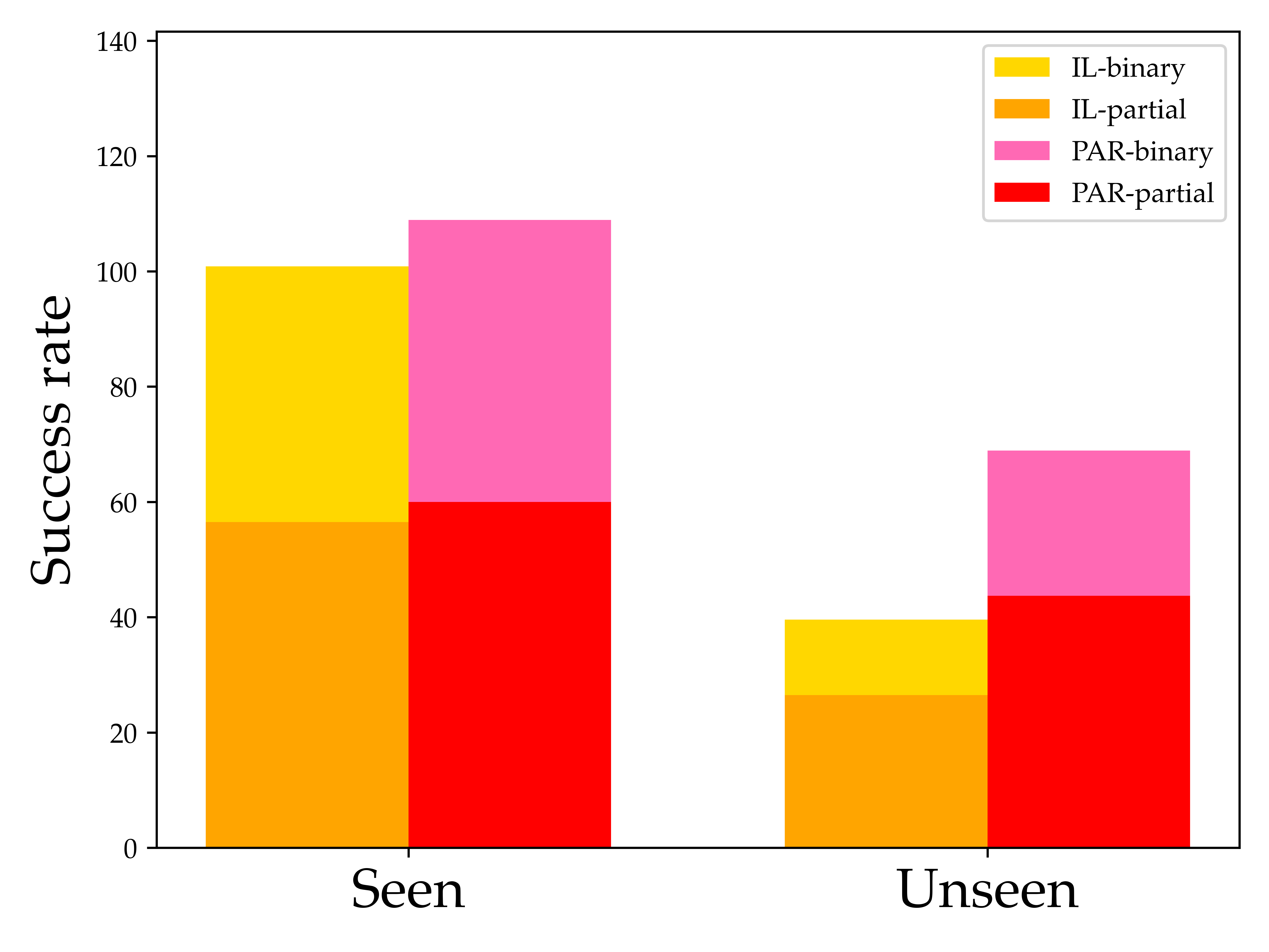
The above figure shows how the two baselines perform on all seen tasks and unseen tasks. Numbers are averages over all relevant tasks. We can see that the imitation learning based CLIPort model (IL) performs a little worse than the Planner-Actor-Reporter based model (PAR) on the seen tasks. However, when generalizing to the unseen tasks, the IL model drops quit a lot while the PAR counterpart can have almost the same performance as on the seen tasks. The binary success rate of both models is quite low, indicating it's very hard for them to finish all the steps of the long-horizon tasks.
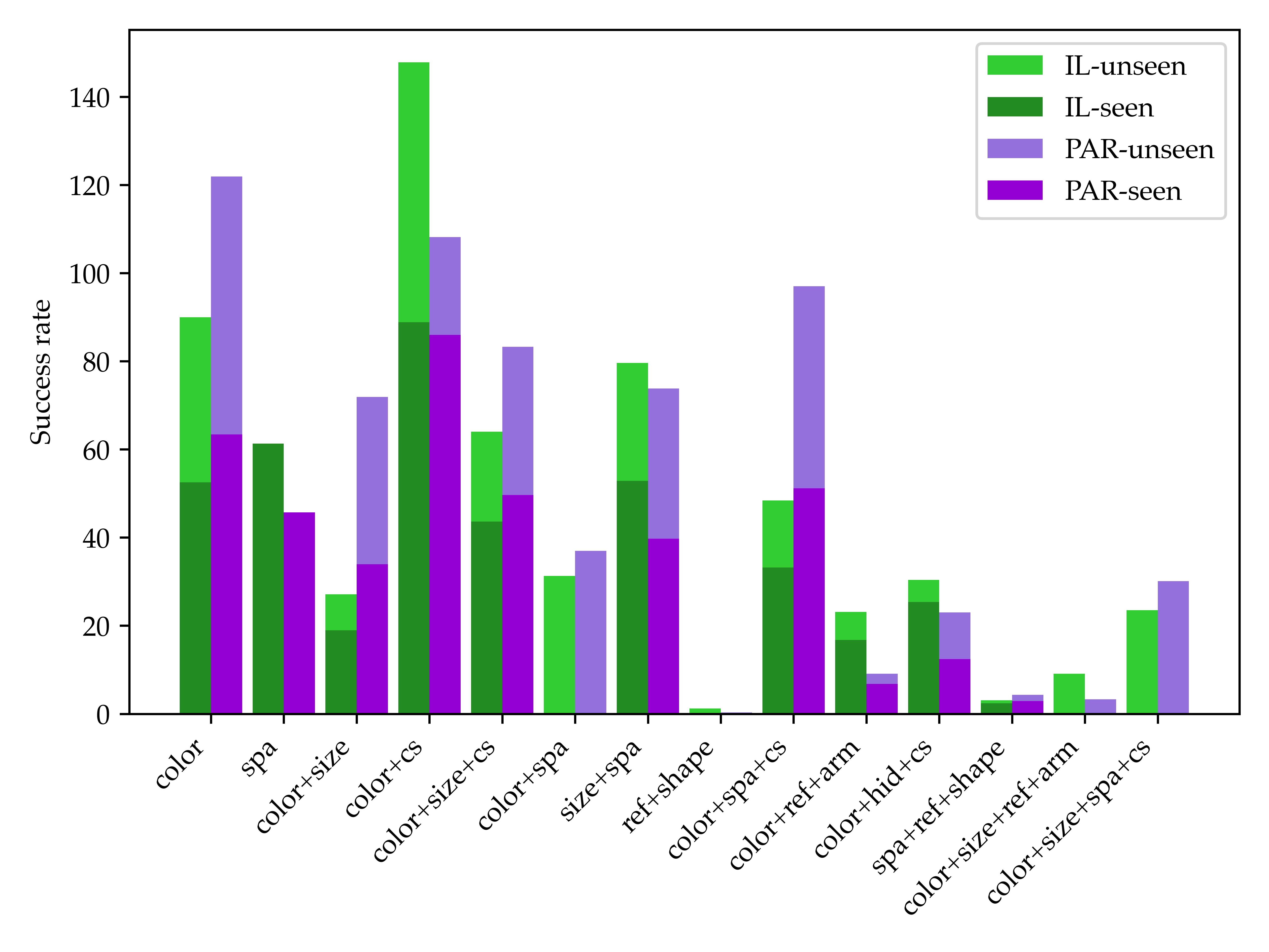
As we can see from the above figure, the overall tendency is that the models' performance drops as the number of combinations of reasoning increases. This observation fits with our intuition that the more reasoning capabilities the tasks require, the harder the tasks become. But there are still some exceptions violating this rule. Unexpectedly, the IL baseline performs better on the tasks requiring "color+size" capabilities than on the tasks requiring "color+size+commonsense" capabilities. We speculate the reason is that "color+size+commonsense" tasks typically use commonsense to filter the objects needed to manipulate, thus this kind of task usually requires fewer steps to complete.
Another interesting finding is that the two baselines perform differently regarding different reasoning capabilities. On the seen tasks requiring spatial reasoning capability, the IL model usually performs better. It is probably because current LLMs and VLMs do not have good spatial understanding. In contrast, the PAR model usually outperforms the IL model on tasks requiring commonsense. Another observation is that the PAR model cannot deal with tasks requiring reference since LLMs cannot indicate the objects accurately if there is more than one object with the same size and color. This also prevents the PAR model from solving the tasks requiring arithmetic reasoning since these tasks usually comprise multiple objects of the same kind.
The experiments also show that some tasks are extremely hard for both models. For tasks that contain hidden objects, both models struggle to reason to remove the top object that blocks the bottom target objects. Moreover, they are almost completely unable to solve shape construction tasks. To summarize, LoHoRavens is a good resource to benchmark methods for robotic manipulation. It is also a challenging benchmark that can facilitate future work on developing more advanced models on long-horizon robotic tasks.